关于服务器硬盘故障但带外没有错误日志的排障与报修笔记
情况说明
收到系统发出IO占用率和IO延迟的告警,登录带外排查无任何错误日志,随后进入操作系统使用脚本批量排查smartctl日志,发现存在错误计数,因smartctl并非厂家带外的告警日志,所以特此向Inspur、H3C、Lenovo、DELL进行了咨询,其中提到了一些日志参数的告警,目前已收到H3C、Inspur的回复
厂商对日志中以下内容的告警表示认可并作为报修依据
| 硬盘类型 | 参数 | 翻译 | 说明 | 来源 |
|---|---|---|---|---|
| SSD | ID 5 Reallocated_Sector_Ct | 重分配扇区计数 | 因坏块被重新分配的扇区数量,值越高健康状况越差 | 新华三 |
| SSD | ID 197 Current_Pending_Sector | 当前待处理扇区计数 | 有潜在读写错误、待重新映射的扇区数量(>100更换) | 浪潮/新华三 |
| SSD | ID 187 Reported_Uncorrect | 已报告的不可纠正错误 | 硬盘向主机报告的读/写过程中发生的不可恢复错误次数(>10更换) | 浪潮 |
| HDD | Total uncorrected errors | 总无法纠正错误 | 所有无法纠正的读/写错误之和 | 浪潮/新华三 |
| HDD | Verify total uncorrected errors | 校验无法纠正错误 | 硬盘控制器自检时无法通过ECC纠正的错误总数,高值表示可靠性下降 | 新华三 |
| HDD | Read total uncorrected errors | 读无法纠正错误 | 读取/写入IO时无法通过ECC纠正的错误总数,高值表示可靠性下降 | 新华三 |
| HDD | Elements in grown defect list | 已增长缺陷列表中的元素 | 硬盘运行中登记的坏块数量,用于追踪坏块增长 | @Icenowy于清华TUNA协会技术群组内回复 |
以下是辅助日志,作为协助排障参考,不作为直接依据
| 硬盘类型 | 参数 | 翻译 | 说明 | 来源 |
|---|---|---|---|---|
| SSD | Reallocated Sector Count | 重分配扇区计数 | 记录因物理损坏被替换到备用扇区的次数,数值增加说明介质退化(>500为不可靠) | 浪潮 |
| SSD | CRC Error Count | CRC 错误计数 | 记录主机与硬盘之间传输数据时发生的 CRC 校验错误次数,常见原因包括数据线接触不良、电磁干扰或接口问题,单盘较多则可能为该盘本体故障,多个硬盘则进一步筛查是否位于同一个硬盘背板或同一个SAS端口 | 浪潮 |
| HDD | Non-medium error count | 非介质故障 | 与上方SSD的是一样的意思 | 浪潮 |
清华大学TUNA协会技术群组
感谢@Icenowy于清华TUNA协会技术群组内回复提出参考Elements in grown defect list参数的值,该值是HDD独有的指标,记录的是在使用过长中新发现的物理坏块数,数值持续增长则意味着该硬盘可靠性正在下降
排查过程
对于JBOD模式的硬盘
1 | 使用smartctl直接查询即可 |
对于LSI MegaRAID控制器,RAID模式的硬盘
1 | 由于硬盘由阵列卡接管,所以需要调用MegaRAID驱动程序才可访问 |
进阶脚本
该脚本会在当前目录输出smartctl的日志源码到disk_error_$(date +%Y%m%d_%H%M%S).log文件
推荐使用此单行模式,复制粘贴直接用,不需要创建shell文件
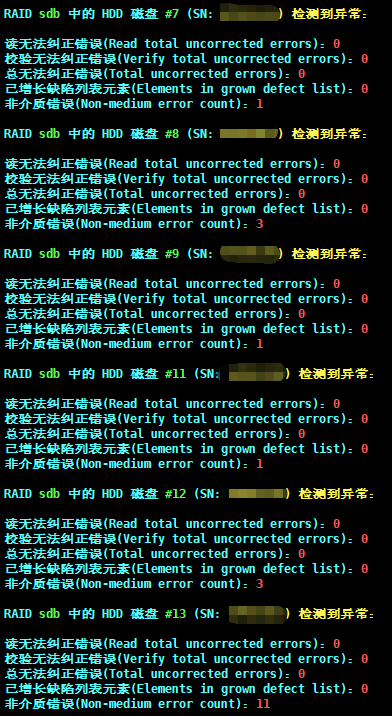
1 | log_file="disk_error_$(date +%Y%m%d_%H%M%S).log"; for raid in {a..d}; do [ -b "/dev/sd$raid" ] && for disk in {0..23}; do smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1 && output=$(smartctl -a -d megaraid,$disk /dev/sd$raid) && serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}') && if echo "$output" | grep -q "SSD"; then reallocated_sectors=$(echo "$output" | grep "Reallocated_Sector_Ct" | awk '{print $10}'); reallocated_sectors=${reallocated_sectors:-0}; current_pending=$(echo "$output" | grep "Current_Pending_Sector" | awk '{print $10}'); current_pending=${current_pending:-0}; reported_uncorrect=$(echo "$output" | grep "Reported_Uncorrect" | awk '{print $10}'); reported_uncorrect=${reported_uncorrect:-0}; offline_uncorrect=$(echo "$output" | grep "Offline_Uncorrectable" | awk '{print $10}'); offline_uncorrect=${offline_uncorrect:-0}; crc_errors=$(echo "$output" | grep "CRC_Error_Count" | awk '{print $10}'); crc_errors=${crc_errors:-0}; [ "$reallocated_sectors" -gt 0 ] || [ "$current_pending" -gt 0 ] || [ "$reported_uncorrect" -gt 0 ] || [ "$offline_uncorrect" -gt 0 ] || [ "$crc_errors" -gt 0 ] && echo "$output" >> "$log_file" && echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 SSD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n\033[36;1m05 重分配扇区计数(Reallocated Sector Count):\033[31;1m$reallocated_sectors\033[0m\n\033[36;1m197 当前待处理扇区(Current Pending Sector Count):\033[31;1m$current_pending\033[0m\n\033[36;1m已报告的不可纠正错误(Reported Uncorrectable Errors):\033[31;1m$reported_uncorrect\033[0m\n\033[36;1m离线不可纠正错误(Offline Uncorrectable):\033[31;1m$offline_uncorrect\033[0m\n\033[36;1m接口CRC错误计数(CRC Error Count):\033[31;1m$crc_errors\033[0m\n"; else read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}'); read_uncorrected=${read_uncorrected:-0}; verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}'); verify_uncorrected=${verify_uncorrected:-0}; total_uncorrected=$(echo "$output" | grep "Total uncorrected errors" | awk '{print $NF}'); total_uncorrected=${total_uncorrected:-0}; grown_defect_list=$(echo "$output" | grep "Elements in grown defect list" | awk '{print $NF}'); grown_defect_list=${grown_defect_list:-0}; non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}'); non_medium=${non_medium:-0}; [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$total_uncorrected" -gt 0 ] || [ "$grown_defect_list" -gt 0 ] || [ "$non_medium" -gt 0 ] && echo "$output" >> "$log_file" && echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 HDD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n\033[36;1m读无法纠正错误(Read total uncorrected errors):\033[31;1m$read_uncorrected\033[0m\n\033[36;1m校验无法纠正错误(Verify total uncorrected errors):\033[31;1m$verify_uncorrected\033[0m\n\033[36;1m总无法纠正错误(Total uncorrected errors):\033[31;1m$total_uncorrected\033[0m\n\033[36;1m已增长缺陷列表元素(Elements in grown defect list):\033[31;1m$grown_defect_list\033[0m\n\033[36;1m非介质错误(Non-medium error count):\033[31;1m$non_medium\033[0m\n"; fi; done; done |
1 | !/bin/bash |
输出效果如下
关于DELL TSR日志(iDRAC)没有硬盘故障告警的报修办法
DELL通常只认可其自身硬件的告警日志。
在硬盘出现非致命故障,无法直观的在操作系统看到硬盘离线或RAID降级,同时TSR日志中没有记录到硬盘故障,iDRAC网页也没有显示硬盘故障时。
DELL通常不会认可运维工程师提供的smartctl日志和其他非DELL硬件报告的日志,
且有时smartctl也并不能很好的定位故障。
为此和DELL进行漫长的沟通后,最终定下来以下排障方式:

- 带外由故障日志时:提供TSR日志报修
- 带外没有故障日志时:提供TSR日志+perccli64 /call show alilog的日志用于报修
此外还可通过分析上文提到的smartctl日志和以下日志用于综合定位问题:
1 | ls -l /sys/class/block > /tmp/lsblock.txt |
以下是本次案例的记录,可以作为排障及报修的参考
情况说明:
本次是日常巡检时运维平台报障IO延迟大于100ms
随后排查了带外,没有告警,继续排查smartctl,定位slot8存在无法纠正的错误记录1次。
随后向DELL提出报修,并上传TSR日志,但因为没有记录告警,所以DELL并不认可,要求进一步调查故障。
排障过程中针对smartctl -a -d megaraid输出的Error counter log,也就是上文解释的smartctl日志;
其中有巨量的Errors Corrected by ECC的fast纠正错误计数,达到了1737961798次,
针对该项报错,DELL不参考,并且未对此进行分析,所以只能自行分析。
结合硬盘运行时间约5.8年,且几乎从未停机;而这份报错是由RAID卡报告给smartctl,
所以在计数准确性上无法验证,同时鉴于运行了很长时间,计数的累计也是可能的因素;
此处有个疑点:该天文数字般的ECC纠错计数是否可能是整个RAID5阵列的纠错被记录到了其中?
再加上硬盘存在故障长期未发现,导致了频繁的纠错?
以上两个疑问仅为猜测,不过该ECC纠错确实会导致IO延迟增加。
在进一步的排查中发现slot9才是故障盘,且其中的Errors Corrected by ECC的fast纠正为0,
反而是delayed纠正为8396次,因此进一步核实这块盘才是真正的故障盘。
因为fast纠正是常规现象,delayed纠正才是有可能存在问题的,delayed纠正是无法快速纠错时进行的深度纠错
接下来讲如何通过分析perccli64 /call show alilog定位到了真正故障的硬盘
首先,perccli64,顾名思义,这是DELL PERC官方的工具,用于操作DELL RAID卡。
因为日志内容较多,所以选择使用perccli64 /call show alilog > /tmp/target.txt查询适配器日志并输出到文件。
随后使用vscode浏览发现,在35200行日志中,光是PD02和PD09的timeout就出现了11938行,
因此该日志足以说明slot2和slot9这两个硬盘出现了故障,
并进一步结合smartctl日志交叉验证了这两块盘存在故障,也就是上文说的delayed的错误计数。
随后同时将TSR日志和perccli64的alilog适配器日志提交给DELL,DELL认可并以此作为依据成功报修。
1 | PD02的timeout |
2025-10-16最新消息:DELL高级工程师驳回了维修请求
然后给出了下面两篇文章
PowerEdge:某些企业硬盘驱动器上读取和验证 ECC 错误的 SMART 错误率较高
故障盘PD 02/09
slot2、9: TOSHIBA AL14SXB30ENY
slot3-8、10-13: Seagate ST300MP0026
结合上面两篇文章和硬盘情况来看,确实,iDRAC没有报故障,同时smartctl和perccli64调查出所谓的”故障”,恰好是两块TOSHIBA的硬盘。
TOSHIBA的其他硬盘确实也被记录到了文章中,提到了会在perccli64中误报timeout,
结合smartctl记录的ECC纠错数量为天文数字,侧面反映了DELL所说的smartctlECC纠错计数不可靠也是事实。
目前看来,维修诉求被DELL工程师驳回也属于合理范围
且故障仅仅体现在运维监测平台告警IO延迟达到128ms,持续时间不足1分钟,随后恢复
故本次报障取消
补充:
该问题提交给了DELL客户经理
您好,我这边有台XXX PowerEdge XXX,在我们运维监控平台发现告警 IO延迟过高,触发时值: XXXms。
针对该告警我们筛查了TSR日志,并未发现告警记录;
进一步筛查了smartctl日志,发现PD 02/09存在 perccli64告警 Command timeout on PD 02/09;
且smartctl记录到ECC delayed纠正8XXX次。目前工程师回复提到了smartctl日志错误率,对于某些企业的硬盘仅供参考,实际现象:
其他Seagate硬盘存在1X亿次ECC fast纠错计数,故我们忽略该告警。
故障的PD02/09为TOSHIBA,存在8XXX次 ECC delayed纠错计数,不过尚未出现无法纠错和扇区故障记录,我们暂时忽略。工程师回复提到了perccli64日志告警timeout,文章解释为:
某个供应商的固态硬盘 (SSD) 不支持其中一个命令 (cdb= 4d 00 51 00 00 00 00 00 00 04 00)
复查后发现,PD 02/09恰好是TOSHIBA的硬盘,且在文章中也有提到TOSHIBA的某个型号SSD不支持该命令,且其他Seagate硬盘均为记录该错误。
故我们根据文章内容,忽略该告警。鉴于本次排障报修涉及的日志和排障过程较为繁琐,目前理清楚前因后果之后,XXX要求我询问下您,看看这次的报障是驳回继续观察,还是说直接安排更换?
目前尚未收到回复…